A Sober Look at LLMs in Late 2025
Table of contents
The year of 2025 is getting close to its end. It has been almost exactly 3 years since ChatGPT was released, the application that made large language model (LLM) a term that is mentioned everywhere and in any context. Access to generative AI has become a commodity, or even pushed on users in many products.
But what does an LLM actually do and what is performed by the application around it? Where do we stand in the battle of private and open models, and what does this mean? Do I even need generative AI and do LLMs improve my productivity no matter what I am working on?
I thought a lot about these questions since I got my hands on ChatGPT and “open” challengers like LLaMA, and had the opportunity to work with talented people who know much more about the impact of LLMs than I do. This post is my attempt to cut through the noise and offer a balanced perspective on where LLMs truly stand.
We will start with a high-level technical introductions to LLMs, but you can jump to the short history or even the discussion of productivity effects if you want to save time.
What does an LLM do? An oversimplified explanation
In short, an LLM takes text (which is encoded into numbers) as input and outputs predictions on the next few characters that should follow. I like Miguel Grinberg’s post How LLMs Work, Explained Without Math, which the following brief and high-level summary is inspired by.
When we feed our prompt (the input text) to the LLM, it is not fed into it directly. Instead, it is encoded first into tokens. Tokens are the vocabulary of an LLM and each token can be one or multiple characters long, or represent punctuation. A word can consist of one or multiple tokens. On average, a token has four characters for the English language. The vocabulary of an LLM has generally a size of tens of thousand different tokens, and each token is represented by a unique id.
Let’s take the sentence “The quick brown fox jumps over the lazy dog.” as an example. When encoding the part “The quick brown fox jumps” for OpenAI’s GPT-4, we get the following output:
>>> import tiktoken
>>> encoding = tiktoken.encoding_for_model("gpt-4")
>>> encoding.encode("The quick brown fox jumps")
[791, 4062, 14198, 39935, 35308]
Given such a sequence of tokens as input, what an LLM will do is to predict which token should follow next by calculating a probability for each token in the library. In broad terms, the calculation involves multiplying the input (vector of token ids) with a bunch of matrices that in total have billions or even a few trillions of entries, the so-called weights. While the calculations itself are linear algebra on high-school level, how to train the LLM, i.e., how to determine the weights, and how to make the predictions work reliably is where the “magic” happens. We will touch these parts a bit further below, but the details are outside the scope of this post.
Following our previous example, we would expect that “over” would be the word predicted next. To get to the full sentence of “The quick brown fox jumps over the lazy dog.”, we would need to execute the model several times in a loop. When do we know that an LLM finished generating its response? It will generate an end-of-sequence token, which works quite reliably these days but you might have seen ChatGPT stuck in a loop generating the same text at some point.
It is important to note that the LLM itself does not have any memory. Each time we call it, it will only process the prompt as input while the model remains static. All applications that we see today like processing PDFs, refactoring code or integrating some kind of memory use more or less elaborate ways to integrate these information into the prompt.
Why do LLMs reply human like and seem to reason?
To my knowledge, the short answer today is still: nobody really knows.
In 2022, a Google research team published the highly-cited paper “Emergent abilities of large language models.” which suggests that when LLMs are scaled up in size and the amount of training performed, there are situations where the observed performance of the trained model suddenly jumps. Training in this context is the automated process of determining the weights of the model, as mentioned in the previous section, using training data. How models are trained is a whole research field of its own. For this post, it is only important to understand that training happens in hundreds of thousands of steps. Each step adjusts the weights of the model to improve its performance, and you can stop at any time and use the model. According to the Google paper, training only slightly improves the model’s performance for the majority of steps performed until performance suddenly jumps. This is the point where abilities like arithmetic, chain-of-thought reasoning or learning new tasks from a few examples in a prompt suddenly “emerge” (according to the paper, see figure below). This would suggest that achieving such abilities in LLMs was not possible before only due to technical limitations.
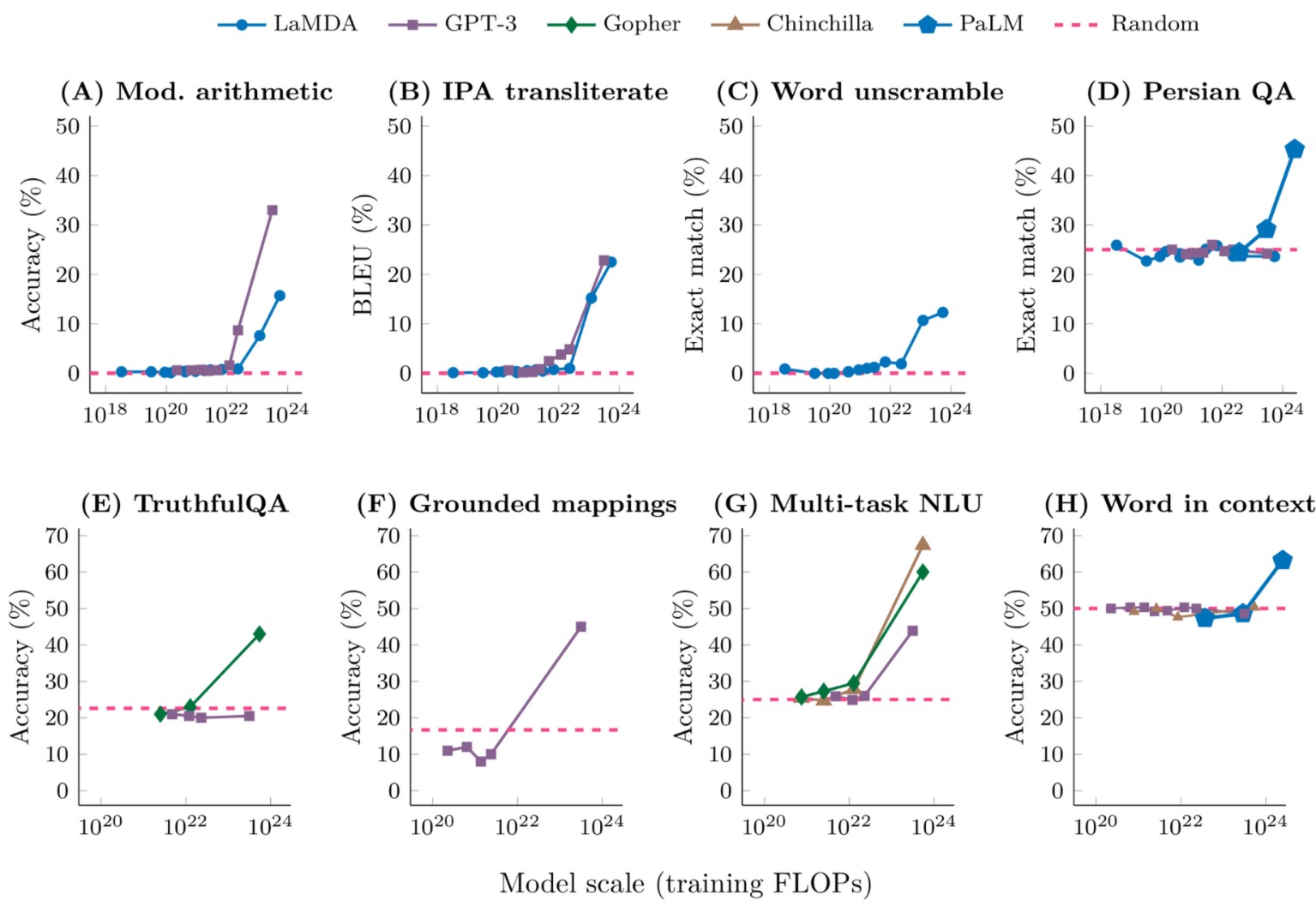
Figure from Wei, Jason, et al. “Emergent abilities of large language models.” arXiv preprint arXiv:2206.07682 (2022).
If it was true that there are “emergent abilities”, we could hope that another jump would occur if we just scaled more with bigger data centers, more data and more training steps. However, the Google paper, and especially the figure, are today seen critically as the majority of emergent abilities disappear when the measurements are presented in a different way. Instead, almost all the abilities see a gradual improvement at scale, not sudden jumps, which is thoroughly shown in the paper “Are Emergent Abilities of Large Language Models a Mirage?" by the STAIR research lab at Stanford.1 As the authors put it, “emergent abilities may be creations of the researcher’s choices, not a fundamental property of the model family on the specific task.”.
So why can LLMs do the things that they can do then? We have now seen that abilities improve more incrementally than initially thought, and some people say it is “just statistics”. While the training of LLMs is explainable by statistics, how a comparably simple training algorithm like gradient descent ends up “discovering” the capable LLMs that we see today is not fully understood. In any case, I think it is fair to say that LLMs (and generative AI in general) are techniques much closer to letting a computer learn and perform a task like a human would as anything before. At the same time, I would argue that it is still far off.
Now that we have some understanding of what LLMs do and demystified the abilities that we see today at least a little bit, let’s zoom out and look at the recent history of LLMs instead of technical details.
How did we get here? A short history on recent LLMs
It is a bit crazy to think that OpenAI’s GPT-2 and GPT-3 were only released in 2019 and 2020, respectively. GPT-2 was OpenAI’s last open model. With around 1.5 billion weights its largest variant was very small compared to today’s standards, but it was surprisingly capable across many language tasks including translations. GPT-3 was released with up to 175 billion weights, and capable enough to be integrated into products like GitHub Copilot. It was also written about quite a bit by the press and philosophers, but by no means did it start the same hype as ChatGPT did. Note, that GPT-3 was released more than two years before ChatGPT (which was based on GPT-3.5).
Broadly speaking, up until 2022 LLMs were mainly trained to complete text or follow single instructions. Conversational models for chat-like interactions existed, e.g., Microsoft’s DialoGPT, Google’s LaMDA or Meta’s BlenderBot, but they were unreliable or locked in research labs. These models took “foundational models” like GPT-2 and GPT-3 but trained them a bit further, so-called fine-tuned, on text that fits the template sketched below:
System: You are a helpful assistant.
User: {question or request}
Assistant: {response}
Instead of performing a specific action or completing an article, these models were trained to complete how an assistant would reply to user requests in a chat. In 2022, however, ChatGPT was the breakthrough application to achieve reliable, somewhat safe conversations that did not derail after a few turns. One of the main ingredients was the large-scale integration of human feedback on conversations to quickly improve the model (RLHF). Instead of locking down ChatGPT behind APIs or in a lab, OpenAI released it for free with an intuitive chat interface. While the established giants Microsoft, Google or Meta might have feared that an unsafe chatbot providing potentially harmful outputs could hurt their reputation, OpenAI could take the risk and quickly improve ChatGPT from user data. The gamble payed off and the rest is history.
The rise of “open” models
If we look at the figure below, Google’s U-PaLM model was more capable than ChatGPT when ChatGPT was released right before 2023, but U-PaLM never became a public product. OpenAI improved and soon took over the lead in LLM capability with GPT-4 in March 2023.

History of Major LLMs (from informationisbeautiful.net)
Just a few weeks before GPT-4, Meta’s LLaMA (Large Language Model Meta AI) was released to selected researchers and quickly leaked to a wider public. This event had a huge impact on research and innovation. LLaMA was not only very capable compared to the models at that time but achieved this at a size that could be run and even fine-tuned on higher-end desktop computers. While at RISE – Research Institutes of Sweden, I fortunately had project budget for a simulation computer and made sure to equip it with the latest and greatest Nvidia gaming GPU at the time (RTX 4090). Being able to run such an LLM locally, was incredible at the time and sparked a lot of research ideas for the safety-critical sectors we were working on.
Up until the release of LLaMA, it was widely believed that only the US Big Tech research labs will have access such capable LLMs for the foreseeable future. LLaMA, and the developments it sparked, motivated the leaked Google memo “We Have No Moat And neither does OpenAI”. The memo by an unknown author predicted that “open source alternatives” will eventually outrun closed models like the ones from Google and OpenAI.
As the figure above shows, a lot of significant LLMs have been released since then, but let’s fast-forward to the beginning of 2025 and the release of “Deepseek R1” by the Chinese AI company Deepseek. Even if LLaMA showed that anyone will be able to run capable LLMs, it was still believed that only US Big Tech will have the hardware to train these kind of models. The assumption was that export restrictions on the most capable GPUs would especially hinder China from achieving this kind of technology. Deepseek R1 proved this wrong, it was trained with much less compute requirements than previous models of the same caliber, which led to considerable drops on US stocks. Like LLaMA, it was further released with “open weights” for anyone to download but much more capable (and more weights than what a 2025 gaming GPU can run).
Since then, the capabilities improvements of the LLMs itself have stagnated but models are getting more efficient (capability per number of weights). Furthermore, additional Chinese competitors have joined the race including Qwen, Z.ai or Moonshot AI, who release many of their models with open weights. Notably, Moonshot AI recently (November 2025) released “Kimi K2 Thinking” which is available as open weights and outperforms the latest closed models by OpenAI (GPT-5) and Anthropic (Claude Sonnet 4.5 Thinking) in several tasks.
Before moving to the next point of discussion, I want to clarify that “open weights” and “open source” are not the same thing. Open weight models can be downloaded and run by anyone (with the right hardware), they can even be fine-tuned for specific tasks, but they are not reproducible. Usually, the data open weight models were trained on is only vaguely described and the code for training the model is missing. Apertus by EPFL, ETH Zurich, and the Swiss National Supercomputing Centre as well as OLMo by the Allen Institute for Artificial Intelligence are truly open models, including source code and training data.
Data is the new moat
What does it mean when US Big Tech companies are not the only ones who can train the most capable models and they are even released for anyone to run? Certainly, the model itself becomes less of a moat (i.e., competitive advantage, referring to the Google memo mentioned above), if it remains one at all. Instead, the applications that are built around the LLMs are getting more important. They serve two purposes: data gathering and infrastructure integration.
Data gathering partially serves model improvement for specific use cases and customers. It further increases the lock-in that companies and public authorities already face today. I do not think that it will stop, however, with enterprise subscriptions to LLM-based products like ChatGPT, Cursor, Copilot, etc., we will see more direct integrations into companies’ infrastructure. For example, Agentic AI was a huge topic this year, where the output of LLMs is not used directly but can trigger tools (like web search or applications) to perform tasks and eventually create more valuable output more reliably. So far, there are few real-life use cases (coding and customer support being the main ones), and they come with serious issues. Once they work more reliably, however, I would expect to see a clear push to make Agentic AI an irreplaceable part of companies’ operations. For example, by embedding autonomous agents into core workflows, decision-making, and data infrastructure with the aim to increase the platform dependency that we already see today.
How to escape data gathering
So far, it is surprisingly easy to leave behind proprietary applications like ChatGPT, Claude, Cursor or whatever LLM-based application you might use for chatting or code generation, and it is something that I really recommend to do. OpenRouter is for example a service that provides unified API access to hundreds of LLMs. Any halfway popular model usually appears within a few days (including the ones from US and China). Fortunately, the OpenAI API has become an industry standard which OpenRouter and other LLM providers use, so you are not locked in by using it.
OpenRouter provides privacy benefits over using proprietary applications. First, because you can choose from numerous providers. For example, Kimi K2 Thinking is hosted by several providers in China and the US. Then, you can filter providers to only use ones that do not train on your data, or have a Zero Data Retention (ZDR) policy.
If you want to go further than using OpenRouter, you can use domestic providers like Berget AI in Sweden directly instead of OpenRouter. This can limit your choice of models but ensures that your data will not leave your country.
Once you moved to an LLM API service (say OpenRouter or Berget AI), you can combine it with the application of your choice. For open source examples, Jan is a popular local application (your chat history will stay on your machine2), Open WebUI is something like a self-hosted ChatGPT, and Void is an alternative to coding tools like Cursor. When using an LLM API service, you will pay per call to the LLM, which can be surprisingly affordable for casual use. It is worth noting that many proprietary applications (like ChatGPT Plus or Claude Pro) are likely sold at a loss to build market share, a strategy that may not be sustainable. In my opinion, this is a very interesting topic of its own but outside the scope of this post.
In summary, it is today quite easy for individual users to take control of their data by moving to LLM API providers and combining it with open source applications. For business contexts, however, I would expect the same push for tight infrastructure integration and lock-in we already see with communication or office software and cloud infrastructure. As an individual, it is easy to move to say Linux, Libreoffice, Nextcloud and Mattermost, but moving your company’s infrastructure out of integrations with Microsoft, AWS, or Google that have grown over years or decades can feel impossible.
But wait – do I even need LLMs?
So far, I have not said much about to what extent LLM-based tools are useful or not in becoming more productive. Most studies on this topic focus on short-term productivity gains of individuals instead of long-term gains across an organization3. The data shows that LLMs unquestionably increase productivity for individuals for less complex tasks like drafting texts or basic coding. When it comes to more complex tasks like strategy development, legal or academic work, creative or innovation tasks, the results become mixed and tasks can even be slowed down.
I find “Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity” by METR particularly interesting, because it focused on experienced developers in large and complex projects. As seen in the figure below, despite expert forecasts and developers perceived productivity gain when using AI to perform coding tasks in large and complex projects, they were actually slowed down considerably. This does not mean that LLMs are generally bad for coding tasks, but suggests that the benefits vanish with increasing complexity and developer familiarity with the project. Instead, over-relying on an unreliable LLM risks to slow down development. Surprisingly, this happens without the developer noticing.

Key finding in Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity (Figure 1)
A recent review article “AI and jobs. A review of theory, estimates, and evidence” by del Rio-Chanona, et al. synthesises findings from dozens of recent studies on the impacts of generative AI (GenAI, which LLMs belong to). It contains extensive discussions and findings which are worth reading, but for the scope of this post I want to quote the following conclusions:
The complexity of the labour market impact of AI becomes even more evident when considering the experimental evidence. Controlled experiments reveal AI’s mixed effects on productivity and employment. While AI tools can significantly enhance productivity in simple tasks, they can also lead to poorer outcomes in more complex tasks, including diminished performance and worker displacement.
[…]
At the same time, AI adoption raises important questions about team dynamics and the reorganization of labour within firms. As AI tools take on more collaborative roles within teams, the boundaries between human and AI contributions may blur. While these innovations promise to enhance productivity and streamline decision-making, they also risk creating over-reliance on AI, which could undermine human judgment and the collective intelligence that typically drives successful teamwork. Moreover, GenAI tools show a ”regression to the mean” (Ernst, 2025), which reduces diversity of output, often an essential ingredient for successful innovations.
In essence, the very tools designed to boost productivity can, in complex, collaborative environments, simultaneously slow us down and risk making our work less innovative. The findings are more general than the METR study mentioned above and do not focus on development tasks alone. They are consistent with the finding that there is a complexity limit for tasks until which today’s GenAI tools provide productivity benefits. Furthermore, the risks for successful teamwork and innovation are from my point of currently view not considered in discussions about introducing GenAI tools at companies.
Discussion: so where do we stand?
From my experience, the discussions about LLMs or generative AI in general are quite polarized. It is difficult to get a sober picture between frustrated employees who are pushed to use AI for everything they do or developers having to increasingly deal with AI slop, and the aggressive marketing by US Big Tech.
Summarizing my thoughts so far, I would say that
- LLMs provide real productivity gains, especially for less complex tasks, but have to be used with caution and their impact on teamwork considered.
- The rapid improvements of LLMs itself seem to lose some traction, capability improvements will presumably come from further integration with tools and infrastructure. However, I see fundamental security challenges here, for example because LLMs cannot differentiate between data and instructions.
- Open-weight models have made LLMs a commodity, even the most capable models can be downloaded by anyone while they are becoming increasingly efficient. This drives hardware requirements down, and makes us less dependent on US Big Tech.
- The push we see today for integrating LLMs into companies workflows and infrastructure is only the beginning, the data and monthly payments it provides is the only chance for training and running LLMs profitably.
Is it a bubble?
Whether the current AI investments are a bubble or not, is currently highly debated. My opinion is that GenAI is slowly reaching a crossroads: either a killer use case or breakthrough innovation is found, or we will see the burst of a bubble. The current investments in GenAI are a bet for the former. For example, the Nvidia stock reached $1 trillion valuation in May 2023, $2 trillion in February 2024, $3 trillion in June 2024, $4 trillion in July 2025 and $5 trillion in October 2025. If the Nvidia stock is some kind of thermometer, we certainly have a fever. Do not get me wrong, though, I expect that LLMs and GenAI in general are here to stay, even when the bubble bursts. Personally, I think that we will have to learn to deal with their impact on our work and the work of our teams whether we like it or not.
What will happen post-hype?
Whether we call it the burst of a bubble or not, I am convinced that there will be a correction. When or how big it will be is anyone’s guess. After the hype, I would expect AI research and development to refocus on trustworthy, explainable and integrated AI. While today’s, GenAI-based tools still regularly produce garbage, we will focus more on AI tools that are robust and produce deterministic results. I would further expect AI tools to become more explainable and better integrate into systems with safety and security constraints, including legacy systems and production pipelines.
This could be a chance for the EU industry, which is strong in building safe and reliable systems. It would be naive, however, to expect the push for integrating their AI into everything from US Big Tech to disappear, it might just get another name. These companies are highly profitable, sit on tremendous amounts of money, and the burst of a bubble will give them ample opportunity to buy companies and hire talent at a discount.
Conclusion
This post is the result of many thoughts and discussions over a longer period of time. It feels a bit like a brain dump, and it might be what this is, but I hope that you still found it coherent to read. If there is one simple takeaway from this post it is: LLMs are useful, but they are not magic and they bring trade-offs that deserve careful thought.
For individuals, the path forward could mean to experiment openly, but carefully. The thriving ecosystem of open-weight models and API providers means you can benefit from this technology without surrendering your data or judgment. Using LLMs for drafting, brainstorming, or learning new APIs seems reasonable, but make sure you keep the final say over quality and correctness. The moment you stop noticing when the AI is wrong might be the moment it starts slowing you down.
For organizations, the stakes are higher. The productivity gains are real but fragile, and the potential long-term costs in terms of lock-in, teamwork, and innovation, are poorly understood. Tighter integration into workflows increases lock-in. My recommendation is to ask whether you are solving a real problem, and can measure real outcomes, or are just following a trend. The data you feed these systems today will become the vendor’s competitive advantage tomorrow, not yours.
The current trajectory feels unsustainable. The bubble may not burst dramatically, but a correction is coming. The future belongs to those who figure out how to integrate AI thoughtfully, where it actually helps, and with safeguards that preserve what makes human teams effective.
-
Schaeffer, Rylan, Brando Miranda, and Sanmi Koyejo. “Are emergent abilities of large language models a mirage?.” Advances in neural information processing systems 36 (2023): 55565-55581. ↩︎
-
Both Jan and Open WebUI make it also quite straight-forward to run LLMs locally, fully offline. Their capabilities will be limited if you do not have a decent GPU, tough, and some tinkering might be needed. ↩︎
-
del Rio-Chanona, R. Maria, et al. “AI and jobs. A review of theory, estimates, and evidence.” arXiv preprint arXiv:2509.15265 (2025). ↩︎